
Technical Summary
The Cosmos supercomputer is built on the HPE Cray Supercomputing EX2500 platform, incorporating innovative AMD Instinct™ MI300A accelerated processing units (APUs), HPE Slingshot interconnect and a flash-based filesystem. The APU uniquely features an in-chip memory layout, which is integrated and shared between CPU and GPU resources. This type of memory architecture facilitates an incremental programming approach, which enables many communities to adopt GPUs and ease the process of porting and optimizing a range of applications. The high-performance VAST filesystem incorporates flash-based storage and provides the high IOPS, and bandwidth needed for the anticipated mixed-application workload
Cosmos is an NSF-funded system, developed in collaboration with CRAY and operated by the San Diego Supercomputer Center at UC San Diego.
Resource Allocation Policies
- Current Status: Testbed Phase
- 3-year testbed phase will be available to select focused projects, as well as workshops and industry interactions.
- The testbed phase will be followed up with a 2 year allocation phase to the broader NSF community and User workshops.
- To get access to Cosmos, please send a request to HPC Consulting.
- All user must review and agree to Cosmos AUP.
Technical Details
- 42 nodes, each with 4 APUs in a fully connected network based on AMDs Infinity xGMI (socket-to-socket global memory interface) technology, which provides 768 GBps aggregate and 256 GBps peer-to-peer bi-directional bandwidth between APUs. xGMI is the equivalent of NVIDIA’s NVLink. The cluster is managed by the SLURM scheduler, which orchestrates job distribution and execution.
- 168 AMD MI300A APUs. The MI300A combinesx86 CPU cores, CDNA3 GPU compute +shared memory access between CPU and GPU. Each APU has a theoretical peak performance of 90 fp64 (HPC) TFLOPS and 760 fp16 (AI) PFLOPS. Accounting for power limits, the whole system will provide close to 10 HPC PFLOPS and 100 AI PFLOPS of usable performance.
- A high-performance interconnect based on HPE’s Slingshot technology, which provides low latency and congestion control.
- 300 TB of high-performance storage from VAST that provides the high IOPS and bandwidth needed for the anticipated mixed-application workload.
- 5 PB of Ceph capacity storage to provide excellent I/O performance for most applications and to store persistent project data.
- Home File System via access to SDSC’s Qumulo storage, which provides a highly reliable, snapshotted file system.
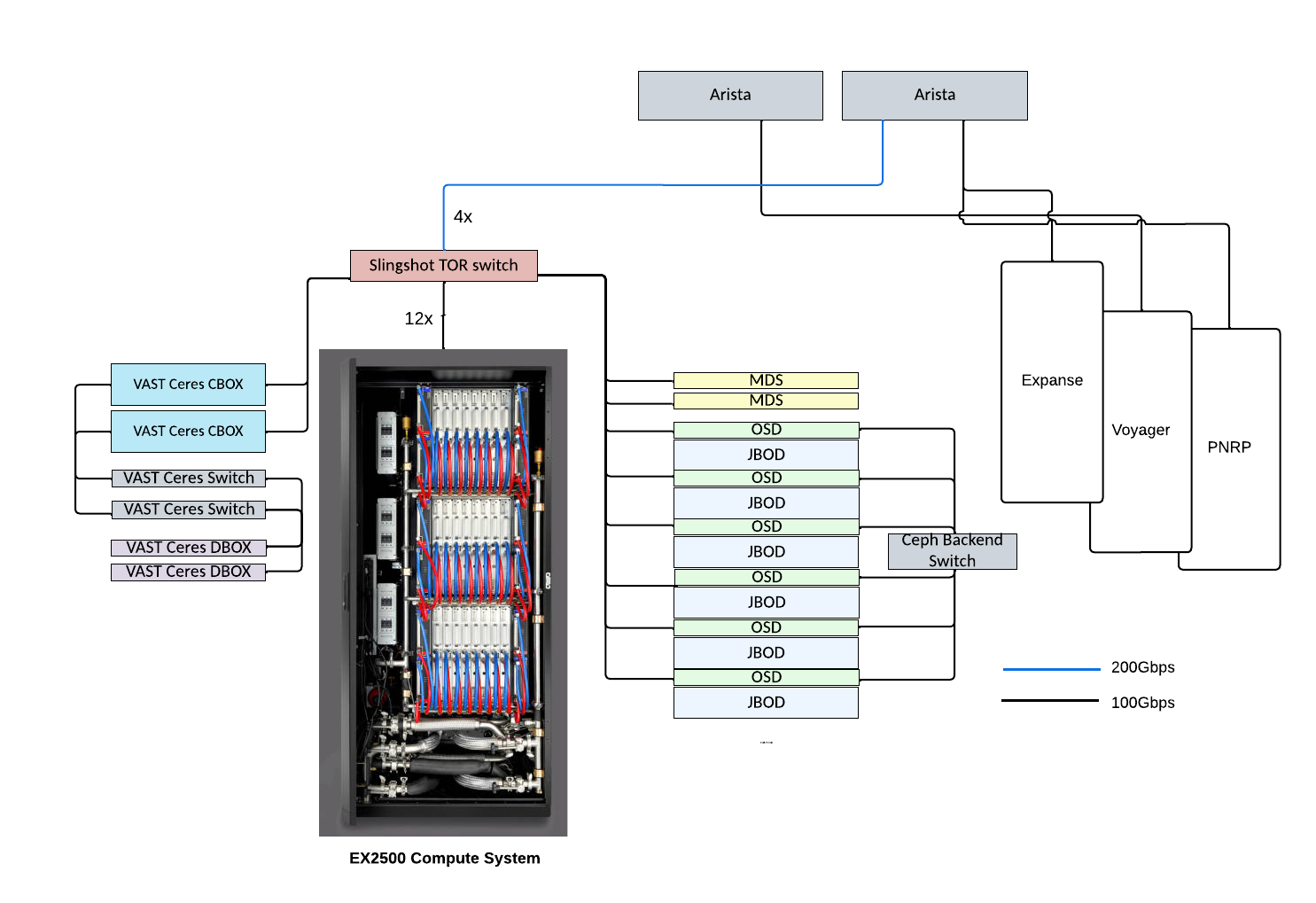
| System Component | Configuration |
|---|---|
| HPE EX2500 MI300A Compute Nodes | |
| MI300A APUs | 168 |
| APUs/node | 4 |
| Nodes/blade | 2 |
| EPYC Zen4 cores per APU | 24 |
| CDNA4 GPU cores per APU | 228 |
| Interconnect | |
| Topology | Dragonfly |
| Network | Slingshot (ethernet-based) |
| Link Bandwidth(bi-directional) | 200GB/s |
| Performance Storage | |
| Capacity | 200TB (usable) |
| Bandwidth (R-W) | 100:10 GB/s |
| IOPS | 676,000 |
| File system | VAST NSF |
| Network | Ethernet |
| Capacity storage | |
| Capacity | 5 PB (usable) |
| Bandwidth | 25 GB/s |
| File systems | Ceph |
| Network | Ethernet |
| Home File System Storage | |
| Capacity | 200 TB (expandable) |
| Filesystem | Qumulo NFS |
| Network | Ethernet |
| Service Nodes and Switching Rack | |
| Login Nodes | 2 |
| Admin and Fabric Nodes | 4 |
| Top of rack Slighshot Switch | 1 |
| Top of rack Aruba management and space switches | 4 |
| 1Gbe management switch | 1 |
Systems Software Environment
| Software Function | Description |
|---|---|
| Cluster Management | HPE Performance Cluster Manager (HPCM) |
| Operating System | SUSE Linux Enterprise Server |
| File Systems | Ceph, Qumulo, VAST |
| Scheduler and Resource Manager | SLURM |
| User Environment | HPC Cray programming environment |