
StarNet AI Expands the Scale of Cosmology Simulations
NSF-funded supercomputers at SDSC, TACC advance deep learning surrogate models for primordial star formation and feedback
Published May 20, 2026
University of California San Diego Halıcıoğlu School of Data Science and Computing astrophysicist Mike Norman is driving a new generation of cosmology simulations that push precision structure-formation modeling to petascale levels and beyond.
In a recent study in The Astrophysical Journal, Norman and collaborators combine GPU‑accelerated cosmology codes with an AI‑driven surrogate model called StarNet to track how matter clumps and evolves over cosmic time, yielding predictions for current and upcoming sky surveys.
To make this happen, Norman and the team used U.S. National Science Foundation Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) allocations on the Expanse system at the San Diego Supercomputer Center (SDSC) as well as the NSF-funded Frontera system at the Texas Advanced Computing Center (TACC).
The researchers built on decades of work in large‑scale structure and galaxy cluster simulations, where numerical models track the interplay of dark matter, gas dynamics, gravity and cosmic expansion in massive, three‑dimensional volumes.
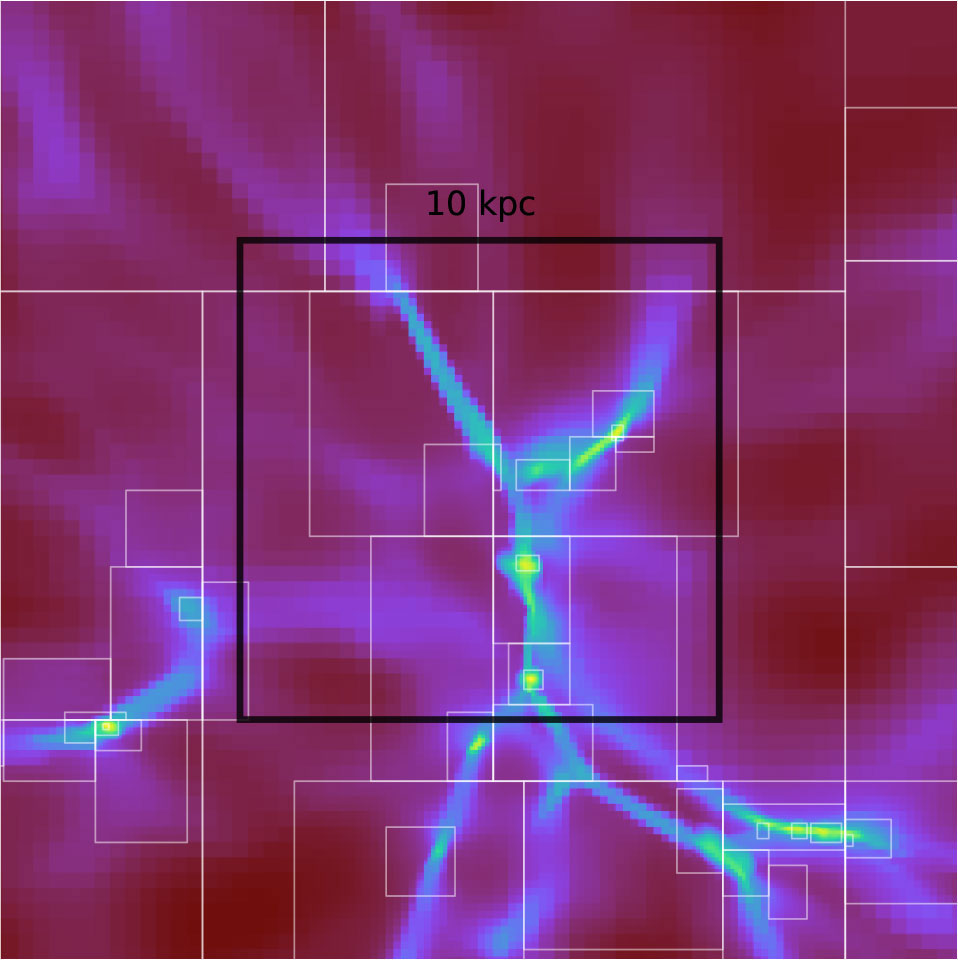
The black box shows the region where the model predicts new star formation, and the surrounding boxes are refined to the same resolution. Credit: Mike Norman, SDSC, UC San Diego Halıcıoğlu School of Data Science and Computing
StarNet is a deep learning surrogate model for primordial star formation and feedback that was trained on over 100 terabytes of high‑resolution simulation data provided by and later validated on Frontera, which was embedded into larger cosmological runs on Expanse to represent unresolved small‑scale physics.
A 3D convolutional neural network pulses through the AI heart of StarNet. The AI component is called StarFind, designed and built using PyTorch on Expanse. StarFind is then combined with a simple machine learning regression model called FBNet to complete the StarNet.
"The main result is a fast, accurate AI/ML surrogate model for incorporating subgrid physics into hydrodynamic cosmological simulations, specifically the formation of primordial stars (Population III) and their supernova feedback effects. Our study describes the design, implementation, training, and validation of the model," said Norman, who was the SDSC director from 2010 to 2021.
A key player on the team is former UC San Diego graduate student Azton Wells, now an associate computational scientist at Argonne National Laboratory. Norman said that Wells played a significant role in the development of StarNet.
“Wells and I utilized Expanse’s scalable compute units and high‑performance interconnect to run suites of simulations that combine traditional adaptive‑mesh cosmology codes with StarNet, allowing us to vary cosmological parameters and sub‑grid models while still capturing the impact of the first stars and their metal enrichment on subsequent galaxy formation,” Norman said. "This ensemble approach allows us to quantify uncertainties and generate more realistic predictions for observables such as X‑ray, Sunyaev–Zel’dovich and weak‑lensing signals from clusters across cosmic time.”
Expanse Architecture and Workflow
Expanse is one of SDSC’s NSF‑funded high-performance computing systems, designed for “computing without boundaries” and composed of hundreds of AMD EPYC CPU nodes, GPU nodes and a modular design based on SDSC Scalable Compute Units (SSCUs) interconnected to high‑performance storage. The system supports both traditional batch jobs and science gateways, enabling Norman’s group to combine large production runs with downstream analysis and AI‑assisted workflows that incorporate models like StarNet.
Recent NSF supplements have added a NAIRR‑funded partition of Dell XE9640 GPU nodes attached to Expanse, each with four NVIDIA H100 GPUs and dual 36‑core Intel Sapphire Rapids CPUs, along with additional multi‑petabyte Ceph storage for data‑intensive workflows. This evolving architecture allows Norman’s team to experiment with hybrid CPU–GPU strategies for both the main simulation codes and the StarNet inference steps, test AI‑assisted analysis on simulation outputs and scale to larger parameter studies without re‑architecting their workflows.
The Role of Frontera
Norman describes the development of a surrogate model for HPC simulations as a four-step process. First, run a full resolution simulation that contains the phenomena you want to capture in the surrogate model. "In our case that was a suite of three simulations called the Phoenix simulations run on Frontera in which Population III star formation and feedback is explicitly simulated," he said.
Next, data was transferred to disk for every star forming event in the simulations, which is used as training data for the surrogate model. "Altogether, we logged over 70,000 star formation events across the three simulations. With that, we designed a 3D convolutional DNN (deep neural network) that observes and classifies the star formation data saved to disk.”
With enough training data, the DNN learns how to connect physical inputs, such as the number and masses of the stars, to physical outputs — the supernova explosion energy and amount of heavy elements ejected into space.
Lastly, the Phoenix simulations were rerun using the DNN in lieu of the explicit star formation and feedback recipes in the original simulations, with the goal of comparing outputs to see if the DNN reproduces the amounts and locations of the star forming regions in the fully resolved simulation.
The Phoenix simulations were run on Frontera over a period of one year and generated large amounts of raw data that had to be pre-processed to be read into PyTorch.
"Moving the data from TACC to SDSC required a good Globus Online connection,” Norman said. “Training StarFind is a long iterative trial and error process to refine the network. That took the most time. Frontera provided the simulation horsepower to run the Phoenix simulations. Expanse (and before it Comet) provided the GPUs used for network design and training.”
The Role of NSF ACCESS Allocations

SDSC’s Expanse operates as a national resource within the NSF’s advanced cyberinfrastructure ecosystem, originally under XSEDE and now via the NSF ACCESS program. Through ACCESS, Norman’s group receives peer‑reviewed allocations that provide the compute hours, storage and support needed to execute multi‑million‑core‑hour campaigns that couple large cosmological simulations with machine‑learning surrogates like StarNet.
These allocations also connect the project to training and consulting services, helping students and postdocs optimize codes, improve I/O performance and adopt new scheduling and workflow tools tuned for Expanse’s architecture. The combination of hardware access and human expertise accelerates time‑to‑science, allowing the team to iterate more quickly between model development, production runs and comparison with survey data.
“Expanse continues to be the workhorse for our cosmology simulations — its mix of CPU and GPU capability, along with support from SDSC staff, lets us tackle problems that simply weren’t feasible a few years ago, especially now that we are embedding AI surrogate models like StarNet directly into our runs,” Norman said. “Equally important, the NSF ACCESS allocations program is what puts this system within reach of our research group; without that national‑scale support, we wouldn’t be running the large ensembles and high‑resolution simulations that drive our science forward.”
The Next Generation of Primordial Star Exploration
StarNet is now part of Enzo-E, the next-generation Enzo code used worldwide for astrophysics and cosmology. Norman plans to continue this work on the NSF Leadership-Class Computing Facility (LCCF) supercomputer, Horizon.
"The combination of Enzo-E, StarNet and Horizon will allow us to carry out the large survey simulations we are targeting. With StarNet, we can accelerate the speed at which we can simulate the early universe allowing us to simulate larger volumes and hence the formation of more galaxies for comparison with observations," he said.
These simulations require a dual capability: high spatial resolution to resolve individual galaxy physics and large volumes to capture statistically meaningful populations. “This can be accomplished with adaptive mesh refinement cosmological hydrodynamic simulations running at full scale on LCCF. On LCCF Phase 1 (Frontera), we have developed the Enzo-E application to do just this. We are optimizing Enzo-E's performance on TACC's Vista supercomputer in anticipation of Horizon.”
"High-end computational resources like those through the LCCF are essential to decoding the discoveries being made using the new generation of telescopes like the James Webb Space Telescope,” Norman said. “Simulations and observations are complimentary ways of learning about the early universe. Used together, we can learn new amazing things about our universe and how it got to be the way it is.”
Support on Expanse is provided by NSF ACCESS (allocation no. AST200019). Learn more about Horizon allocations.