The theoretical speedup for the BBN as a function of N and W can be computed
using
the calculated values for the serial fraction, f, given in table 5.2. When
this
is
done, the results compare quite poorly with the observed speedups tabulated
in table 5.1. This indicates that the parallelization overhead cannot
be ignored, and one needs
to include a non-zero ![]() in the equation for speedup i.e., equation
(5.5).
Let us
start with equation (5.5), and assume that
in the equation for speedup i.e., equation
(5.5).
Let us
start with equation (5.5), and assume that ![]() can be modeled as follows:
can be modeled as follows:
| (118) |
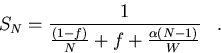 |
(119) |
This expression for speedup is used to find values of ![]() that would force the
predicted speedups to match the observed speedups given in table 5.1. These
``required''
values of
that would force the
predicted speedups to match the observed speedups given in table 5.1. These
``required''
values of ![]() show a trend in
show a trend in ![]() somewhat independent of W but
nearly
linear with N, the number of processors. Therefore,
somewhat independent of W but
nearly
linear with N, the number of processors. Therefore, ![]() was modeled
as follows:
was modeled
as follows:
| (120) |
This expression is linear with N and the constant 0.0006 appears due to the
fact that
the required ![]() was approximately 0.0006 for N=116, somewhat independent
of W.
Of course, this implies that the overhead term
was approximately 0.0006 for N=116, somewhat independent
of W.
Of course, this implies that the overhead term ![]() is not linear in
N but quadratic:
is not linear in
N but quadratic:
| (121) |
This O(N2) dependence may be due to memory contention resulting from the BBN implementation of the message passing system, LMPS, which relies on the shared memory features of the BBN.
This expression for ![]() in equation (5.17) was then used in equation (5.16)
to predict
the speedups for the five different workloads and the number of processors
varying from 1 to 116.
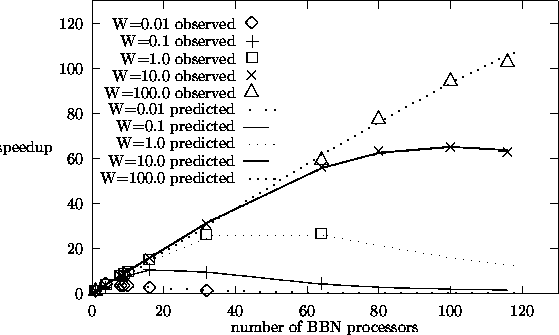
The results are shown in figure 5.3. The plots include the observed speedups
from
table 5.1 for comparison. It is clear that this simple model, which uses
two empirical
parameters (f and
in equation (5.17) was then used in equation (5.16)
to predict
the speedups for the five different workloads and the number of processors
varying from 1 to 116.
The results are shown in figure 5.3. The plots include the observed speedups
from
table 5.1 for comparison. It is clear that this simple model, which uses
two empirical
parameters (f and ![]() ), predicts the behavior of the BBN very well
over a wide
range of numbers of processors and workloads.
), predicts the behavior of the BBN very well
over a wide
range of numbers of processors and workloads.