

Technology
Science
Education


Recent Posts
Technology
Science
Education
United Nations Holds Southern California’s First Hackathon at UC San Diego
UC San Diego's recent Reboot the Earth event challenged students and developers to create innovative software for wildfire prevention and...
SDSC Helps MIT Scientists Build Better Models for Complex Materials
MIT researchers used the Expanse supercomputer and AI to map complex metal alloys at the atomic scale, accelerating the design of safer aircraft...
Technology
Education
Science
Supercomputer Center launches at Fresno State
This first-of-its-kind partnership between industry and higher education expands access to advanced computing and AI resources to accelerate...

Science
Technology
Education
SDSC to Host Fast Machine Learning for Science Conference
The conference is an opportunity to examine the vast applications of machine learning in various fields of science and explore emerging ML methods.

Technology
Awards
Science
Google.org Supports the Societal Computing and Innovation Lab to Accelerate AI Wildfire Solutions
Funding will help accelerate the development of wildfire technology using advanced computing, artificial intelligence and integrated workflows.

Technology
UC San Diego Helps Prepare AI Tourism Assistant for World Cup Crowds
As Mexico City prepared for the surge of international visitors expected during the FIFA World Cup, developers behind an AI-powered tourism...

Technology
Science
Looking Beneath the Shell: AI Helps Protect Endangered Abalone
Researchers are helping endangered abalone recover by using supercomputers and AI to determine when they're ready to spawn and whether an...
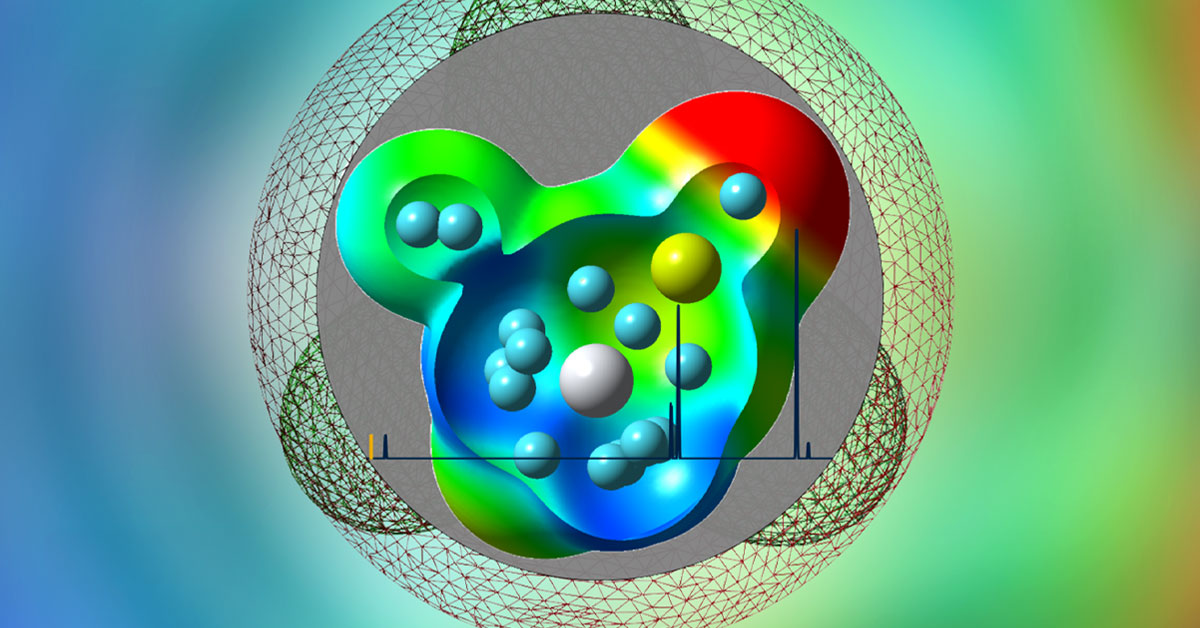
Science
Murray State University's Hydrogen Storage Study, Powered by SDSC's Expanse, Lands on Journal Cover
Scientists are unlocking a safer way to store clean hydrogen energy by mapping exactly how much fuel atomic clusters can hold before filling up.

Awards
Technology
UC San Diego Researchers Win Best Paper Award for New Approach to Connecting Complex Data Systems
Researchers at UC San Diego have developed a new system designed to solve one of modern computing’s growing challenges: how to efficiently...

Technology
SDSC System Launches Secure Environment for NIH Controlled Access Data Research
The Triton Shared Computing Cluster now supports a secure, NIST compliant environment for handling sensitive NIH biomedical data, including...

Technology
Science
Awards
UC San Diego Awarded $4.85M to Grow NEMAR into HPC Hub for Neuro-AI
UC San Diego Awarded $4.85M to Grow NEMAR into HPC Hub for Neuro-AI

Science
Technology
StarNet AI Expands the Scale of Cosmology Simulations
UC San Diego astrophysicists are driving a new generation of cosmology simulations that push precision structure-formation modeling to petascale...

Education
Technology
How SDSC and CENIC Are Bringing AI Infrastructure to California's Classrooms
By centralizing expert operations while allowing colleges to own their hardware, SDSC and CENIC AIR are providing equitable access to advanced...
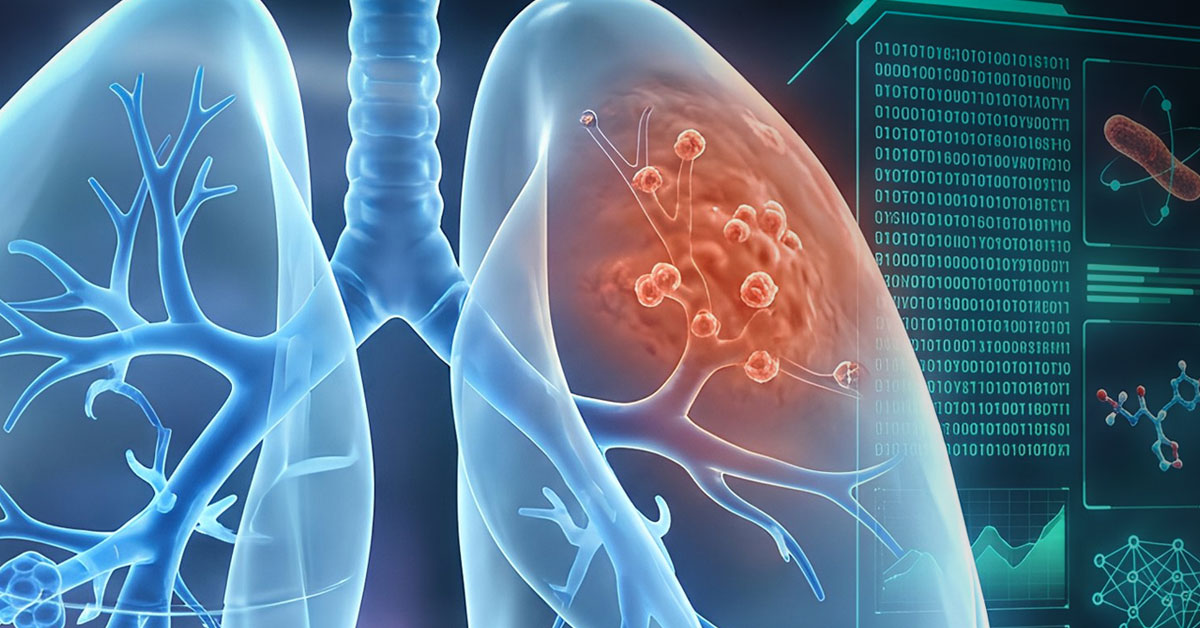
Science
Technology
Using NSF ACCESS Supercomputers to Improve Tuberculosis Treatment Options
Researchers simulated an unprecedented number of tuberculosis drug combinations that may cure infections faster, using less medicine and reducing...

Technology
Science
Education
Using AI to Protect America's Farms from Frost
A California Central Valley initiative held a competition inviting university teams to develop data-driven models capable of predicting frost...

Technology
Science
Cheaper, Longer-Lasting Batteries Are Closer Thanks to a Pinch of Sodium and a Supercomputer
SDSC's Expanse played an important role in helping researchers design next gen sodium batteries that could make large‑scale energy...

Science
Technology
SDSC’s Expanse Helps Illustrate How to Break ‘Forever Chemicals’ in Real Time
Researchers used Expanse to simulate the atomic-level destruction of PFAS chemicals on electrically charged surfaces, thus providing a roadmap to...

Education
Science
Technology
Seeking Leaders for SDSC CORE Institute AI & Indigenous Language Revitalization Cohort
The leadership council will help shape an interdisciplinary cohort focused on building responsible, community-centered approaches to AI in...

Science
Technology
Education
SDSC Interns Drive Innovation in Alzheimer’s Research Data Tools
Student developers recently created a custom database web application that brings new efficiency and collaboration to a program once reliant on...
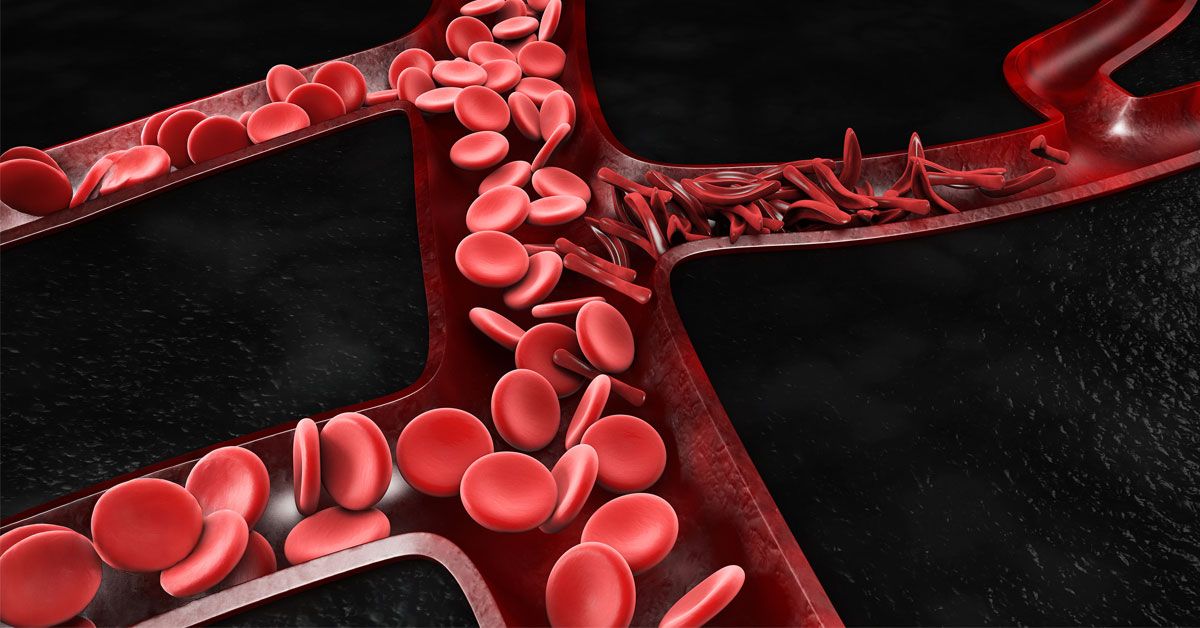
Science
Technology
SDSC’s Expanse Charts the Hidden Toll of Sickle Cell Disease
Patients face elevated risks of stroke, organ damage and chronic pain driven in part by this ongoing vascular injury. Using Expanse, researchers...

Education
Science
Technology
UC San Diego Students Learn HPC Skills via SDSC’s Expanse
At UC San Diego, high performance computing is being woven directly into undergraduate engineering education by giving students early, hands-on...
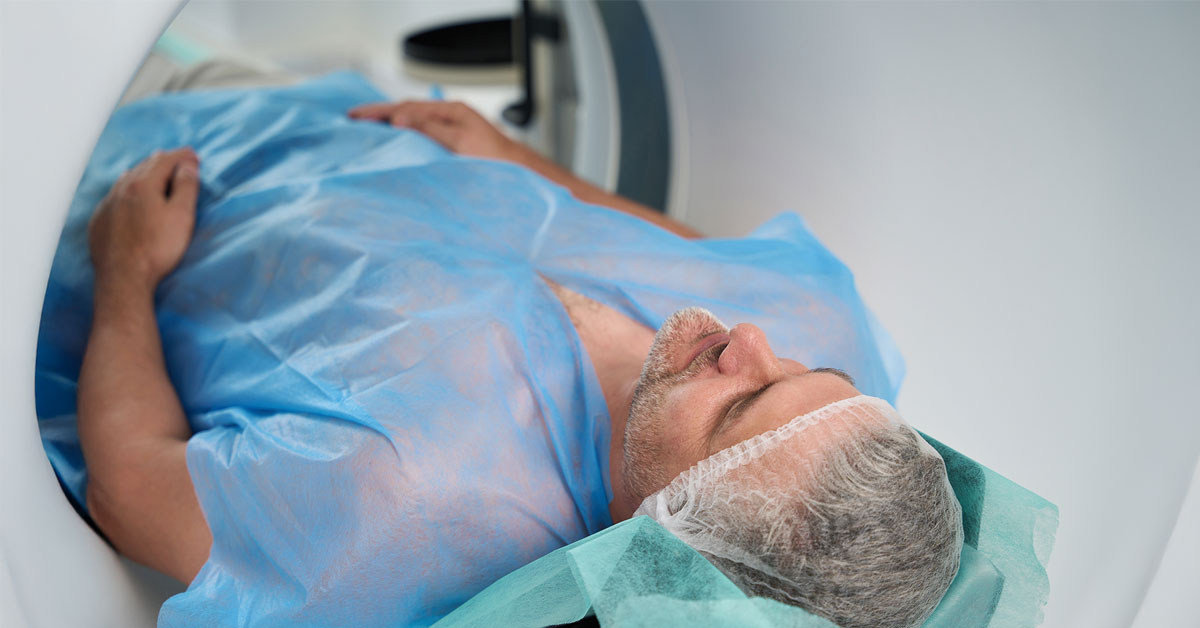
Science
Technology
San Diego Supercomputer Center Powers AI Model to Improve Prostate Cancer Care
A new AI model of the male urinary tract could make prostate cancer radiation therapy more precise and help reduce side effects, such as urinary...

Science
Technology
MIT Scientists Use SDSC Supercomputer to Reveal Hidden Physics Inside Metals
Researchers uncovered a hidden atomic process that challenges long-held assumptions about disorder in metals when they are melted, cooled or shaped.

Education
Science
Technology
SDSC Opens Summer Research Program for Local High School Students
SDSC’s REHS program gives participants hands‑on experience in data‑driven research while working alongside researchers and...
Technology
Science
Empowering Researchers to Decode Complex Biological Systems
From decoding microbial ecosystems to analyzing vast genetic datasets, modern biology increasingly relies on high-powered software tools that can...